ലിനക്സിലെ ഉപയോഗപ്രദമായ egrep കമാൻഡ് ഉദാഹരണങ്ങൾ
ചുരുക്കം: ഈ ഗൈഡിൽ, egrep കമാൻഡിന്റെ ചില പ്രായോഗിക ഉദാഹരണങ്ങൾ ഞങ്ങൾ ചർച്ച ചെയ്യും. ഈ ഗൈഡ് പിന്തുടർന്ന്, ഉപയോക്താക്കൾക്ക് ലിനക്സിൽ കൂടുതൽ കാര്യക്ഷമമായി ടെക്സ്റ്റ് സെർച്ചിംഗ് നടത്താൻ കഴിയും.
ലോഗുകളിൽ ആവശ്യമായ വിവരങ്ങൾ കണ്ടെത്താൻ കഴിയാത്തതിനാൽ നിങ്ങൾ എപ്പോഴെങ്കിലും നിരാശപ്പെട്ടിട്ടുണ്ടോ? ഒരു വലിയ ഡാറ്റാ സെറ്റിൽ നിന്ന് ആവശ്യമായ വിവരങ്ങൾ വേർതിരിച്ചെടുക്കുന്നത് സങ്കീർണ്ണവും സമയമെടുക്കുന്നതുമായ ഒരു ജോലിയാണ്.
ഓപ്പറേറ്റിംഗ് സിസ്റ്റം ശരിയായ ടൂളുകൾ നൽകുന്നില്ലെങ്കിൽ, നിങ്ങളെ രക്ഷിക്കാൻ ലിനക്സ് ഇതാ വരുന്നുവെങ്കിൽ കാര്യങ്ങൾ ശരിക്കും വെല്ലുവിളിയാകും. ലിനക്സ് സെഡ്, കട്ട് മുതലായവ പോലുള്ള വിവിധ ടെക്സ്റ്റ് ഫിൽട്ടറിംഗ് യൂട്ടിലിറ്റികൾ നൽകുന്നു.
എന്നിരുന്നാലും, ലിനക്സിലെ ടെക്സ്റ്റ് പ്രോസസ്സിംഗിനായി ഏറ്റവും ശക്തവും സാധാരണയായി ഉപയോഗിക്കുന്നതുമായ യൂട്ടിലിറ്റികളിൽ ഒന്നാണ് egrep, ഞങ്ങൾ egrep കമാൻഡിന്റെ ചില ഉദാഹരണങ്ങൾ ചർച്ച ചെയ്യാൻ പോകുന്നു.
ഫയലുകളിൽ ഒരു പ്രത്യേക പാറ്റേൺ തിരയുന്നതിനും പൊരുത്തപ്പെടുത്തുന്നതിനും ഉപയോഗിക്കുന്ന grep കമാൻഡിന്റെ കുടുംബം Linux-ലെ egrep കമാൻഡ് തിരിച്ചറിയുന്നു. ഇത് grep -E (grep Extended regex) ന് സമാനമായി പ്രവർത്തിക്കുന്നു, പക്ഷേ ഇത് കൂടുതലും ഒരു പ്രത്യേക ഫയലോ അല്ലെങ്കിൽ ലൈനിലേക്കുള്ള ലൈനുകളോ തിരയുന്നു അല്ലെങ്കിൽ തന്നിരിക്കുന്ന ഫയലിലെ ലൈൻ പ്രിന്റുചെയ്യുന്നു.
egrep കമാൻഡിന്റെ വാക്യഘടന ഇപ്രകാരമാണ്:
$ egrep [OPTIONS] PATTERNS [FILES]
ഒരു ഉദാഹരണം ഉപയോഗിക്കുന്നതിന് ഇനിപ്പറയുന്ന ഉള്ളടക്കങ്ങളുള്ള ഒരു സാമ്പിൾ ടെക്സ്റ്റ് ഫയൽ സൃഷ്ടിക്കാം:
$ cat sample.txt

ഇവിടെ, ടെക്സ്റ്റ് ഫയൽ തയ്യാറാണെന്ന് നമുക്ക് കാണാം. ഇപ്പോൾ നമുക്ക് ദൈനംദിന അടിസ്ഥാനത്തിൽ ഉപയോഗിക്കാവുന്ന കുറച്ച് സാധാരണ ഉദാഹരണങ്ങൾ ചർച്ച ചെയ്യാം.
ഒരു ലളിതമായ പാറ്റേൺ-മാച്ചിംഗ് ഉദാഹരണത്തിൽ നിന്ന് നമുക്ക് ആരംഭിക്കാം, ഇവിടെ നമുക്ക് ഒരു സാമ്പിൾ.txt ഫയലിൽ ഒരു സ്ട്രിംഗ് പ്രൊഫഷണൽ തിരയാൻ താഴെയുള്ള കമാൻഡ് ഉപയോഗിക്കാം:
$ egrep professionals sample.txt

ഇവിടെ, കമാൻഡ് നിർദ്ദിഷ്ട പാറ്റേൺ അടങ്ങുന്ന ലൈൻ പ്രിന്റ് ചെയ്യുന്നതായി കാണാം.
പൊരുത്തപ്പെടുന്ന പാറ്റേൺ ഹൈലൈറ്റ് ചെയ്തുകൊണ്ട് നമുക്ക് ഔട്ട്പുട്ട് കൂടുതൽ വിവരദായകമാക്കാം. ഇത് നേടുന്നതിന്, നമുക്ക് egrep കമാൻഡിന്റെ --color ഓപ്ഷൻ ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, ചുവടെയുള്ള കമാൻഡ് ചുവന്ന നിറത്തിൽ പ്രൊഫഷണലുകൾ എന്ന വാചകം ഹൈലൈറ്റ് ചെയ്യും:
$ egrep --color=auto professionals sample.txt

മുമ്പത്തേതിനെ അപേക്ഷിച്ച് ഇതേ ഔട്ട്പുട്ട് കൂടുതൽ വിവരദായകമാണെന്ന് ഇവിടെ കാണാം. കൂടാതെ, professionals എന്ന വാക്ക് രണ്ട് തവണ ആവർത്തിക്കുന്നത് നമുക്ക് എളുപ്പത്തിൽ തിരിച്ചറിയാനാകും.
മിക്ക ലിനക്സ് സിസ്റ്റങ്ങളിലും ഇനിപ്പറയുന്ന അപരനാമം ഉപയോഗിച്ച് മുകളിൽ പറഞ്ഞ ക്രമീകരണം സ്ഥിരസ്ഥിതിയായി പ്രവർത്തനക്ഷമമാക്കിയിരിക്കുന്നു:
$ alias egrep='egrep –color=auto'
egrep കമാൻഡ് ഒന്നിലധികം ഫയലുകളെ ഒരു ആർഗ്യുമെന്റായി സ്വീകരിക്കുന്നു, ഇത് ഒന്നിലധികം ഫയലുകളിൽ ഒരു പ്രത്യേക പാറ്റേൺ തിരയാൻ ഞങ്ങളെ അനുവദിക്കുന്നു. ഒരു ഉദാഹരണത്തിലൂടെ ഇത് മനസ്സിലാക്കാം.
ആദ്യം, sample.txt ഫയലിന്റെ ഒരു പകർപ്പ് സൃഷ്ടിക്കുക:
$ cp sample.txt sample-copy.txt
ഇപ്പോൾ, രണ്ട് ഫയലുകളിലും പാറ്റേൺ പ്രൊഫഷണലുകൾ തിരയുക:
$ egrep professionals sample.txt sample-copy.txt

മുകളിലുള്ള ഉദാഹരണത്തിൽ, നമുക്ക് ഔട്ട്പുട്ടിൽ ഫയലിന്റെ പേര് കാണാൻ കഴിയും, അത് ആ ഫയലിൽ നിന്ന് പൊരുത്തപ്പെടുന്ന വരിയെ പ്രതിനിധീകരിക്കുന്നു.
ഫയലിൽ പാറ്റേൺ ഉണ്ടോ ഇല്ലയോ എന്ന് ചിലപ്പോൾ നമ്മൾ കണ്ടെത്തേണ്ടതുണ്ട്. അതെ എങ്കിൽ, എത്ര വരികളിൽ അതിന്റെ നിലവിലുണ്ട്? അത്തരം സന്ദർഭങ്ങളിൽ, നമുക്ക് കമാൻഡിന്റെ -c ഓപ്ഷൻ ഉപയോഗിക്കാം.
ഉദാഹരണത്തിന്, താഴെയുള്ള കമാൻഡ് ഒരു ഔട്ട്പുട്ടായി 1 കാണിക്കും, കാരണം പ്രൊഫഷണലുകൾ എന്ന വാക്ക് ഒരു വരിയിൽ മാത്രമേ ഉള്ളൂ.
$ egrep -c professionals sample.txt 1
മുമ്പത്തെ ഉദാഹരണത്തിൽ, -c ഓപ്ഷൻ പാറ്റേണിന്റെ സംഭവങ്ങളുടെ എണ്ണം കണക്കാക്കുന്നില്ലെന്ന് ഞങ്ങൾ കണ്ടു. ഉദാഹരണത്തിന്, professionals എന്ന വാക്ക് ഒരേ വരിയിൽ രണ്ട് തവണ പ്രത്യക്ഷപ്പെടുന്നു, എന്നാൽ -c ഓപ്ഷൻ അതിനെ ഒരൊറ്റ പൊരുത്തമായി മാത്രം കണക്കാക്കുന്നു.
അത്തരം സന്ദർഭങ്ങളിൽ, പൊരുത്തപ്പെടുന്ന പാറ്റേൺ മാത്രം പ്രിന്റ് ചെയ്യാൻ കമാൻഡിന്റെ -o ഓപ്ഷൻ ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, താഴെയുള്ള കമാൻഡ് രണ്ട് വ്യത്യസ്ത വരികളിൽ പ്രൊഫഷണലുകൾ എന്ന വാക്ക് കാണിക്കും:
$ egrep -o professionals sample.txt
ഇപ്പോൾ, wc കമാൻഡ് ഉപയോഗിച്ച് വരികൾ എണ്ണാം:
$ egrep -o professionals sample.txt | wc -l

മുകളിലുള്ള ഉദാഹരണത്തിൽ, നിർദ്ദിഷ്ട പാറ്റേണിന്റെ സംഭവങ്ങളുടെ എണ്ണം കണക്കാക്കാൻ ഞങ്ങൾ egrep, wc കമാൻഡുകളുടെ സംയോജനം ഉപയോഗിച്ചു.
ഡിഫോൾട്ടായി, egrep ഒരു കേസ് സെൻസിറ്റീവ് രീതിയിൽ പാറ്റേൺ പൊരുത്തപ്പെടുത്തൽ നടത്തുന്നു. അതിന്റെ അർത്ഥം വാക്കുകളാണ് - നമ്മൾ, ഞങ്ങൾ, നമ്മൾ, നമ്മൾ എന്നിവ വ്യത്യസ്ത വാക്കുകളായി കണക്കാക്കുന്നു. എന്നിരുന്നാലും, -i ഓപ്ഷൻ ഉപയോഗിച്ച് നമുക്ക് കേസ്-ഇൻസെൻസിറ്റീവ് തിരയൽ നടപ്പിലാക്കാൻ കഴിയും.
ഉദാഹരണത്തിന്, താഴെയുള്ള കമാൻഡ് പാറ്റേണിൽ we, We എന്നീ വാചകങ്ങൾക്കായുള്ള പൊരുത്തം വിജയിക്കും:
$ egrep -i we sample.txt

മുമ്പത്തെ ഉദാഹരണത്തിൽ, egrep കമാൻഡ് ഒരു ഭാഗിക പൊരുത്തം നടത്തുന്നുവെന്ന് ഞങ്ങൾ കണ്ടു. ഉദാഹരണത്തിന്, ഞങ്ങൾ we എന്ന വാചകത്തിനായി തിരഞ്ഞപ്പോൾ മറ്റ് ടെക്സ്റ്റുകൾക്കും പാറ്റേൺ പൊരുത്തപ്പെടുത്തൽ വിജയിച്ചു. വെബ്, വെബ്സൈറ്റ്, എന്നിവ പോലെ.
ഈ പരിമിതി മറികടക്കാൻ, നമുക്ക് -w ഓപ്ഷൻ ഉപയോഗിക്കാം, അത് മുഴുവൻ പദ പൊരുത്തവും നടപ്പിലാക്കുന്നു.
$ egrep -w we sample.txt

ഇതുവരെ, നൽകിയിരിക്കുന്ന പാറ്റേൺ ഉള്ള വരികൾ പ്രിന്റ് ചെയ്യാൻ ഞങ്ങൾ egrep കമാൻഡ് ഉപയോഗിച്ചു. എന്നിരുന്നാലും, ചിലപ്പോൾ ഞങ്ങൾ ഓപ്പറേഷൻ വിപരീത രീതിയിൽ നടത്താൻ ആഗ്രഹിക്കുന്നു.
ഉദാഹരണത്തിന്, നൽകിയിരിക്കുന്ന പാറ്റേൺ ഇല്ലാത്ത വരികൾ പ്രിന്റ് ചെയ്യാൻ ഞങ്ങൾ ആഗ്രഹിച്ചേക്കാം. -v ഓപ്ഷന്റെ സഹായത്തോടെ നമുക്ക് ഇത് നേടാനാകും:
$ egrep -v we sample.txt

ഇവിടെ, we എന്ന വാചകം അടങ്ങാത്ത എല്ലാ വരികളും കമാൻഡ് പ്രിന്റ് ചെയ്യുന്നതായി നമുക്ക് കാണാൻ കഴിയും.
ലൈൻ നമ്പറിംഗ് പ്രവർത്തനക്ഷമമാക്കാൻ കമാൻഡിന്റെ -n ഓപ്ഷൻ ഉപയോഗിക്കാം, ഇത് പാറ്റേൺ പൊരുത്തപ്പെടുത്തൽ വിജയിക്കുമ്പോൾ ഔട്ട്പുട്ടിലെ ലൈൻ നമ്പർ കാണിക്കുന്നു. ഈ ലളിതമായ ട്രിക്ക് ഔട്ട്പുട്ടിനെ കൂടുതൽ അർത്ഥവത്തായതാക്കുന്നു.
$ egrep -n professionals sample.txt

മുകളിലെ ഔട്ട്പുട്ടിൽ, 5-ാമത്തെ വരിയിൽ പ്രൊഫഷണലുകൾ എന്ന വാക്ക് ഉണ്ടെന്ന് നമുക്ക് കാണാൻ കഴിയും.
നിശബ്ദ മോഡിൽ, egrep കമാൻഡ് പൊരുത്തപ്പെടുന്ന പാറ്റേൺ പ്രിന്റ് ചെയ്യുന്നില്ല. അതിനാൽ പാറ്റേൺ പൊരുത്തപ്പെടുത്തൽ വിജയിച്ചോ ഇല്ലയോ എന്ന് തിരിച്ചറിയാൻ ഞങ്ങൾ കമാൻഡിന്റെ റിട്ടേൺ മൂല്യം ഉപയോഗിക്കേണ്ടതുണ്ട്.
ഷെൽ സ്ക്രിപ്റ്റുകൾ എഴുതുമ്പോൾ ഉപയോഗപ്രദമാകുന്ന ശാന്തമായ മോഡ് പ്രവർത്തനക്ഷമമാക്കാൻ കമാൻഡിന്റെ -q ഓപ്ഷൻ ഉപയോഗിക്കാം.
$ egrep -q professionals sample.txt $ egrep -q non-existing-pattern sample.txt

ഈ ഉദാഹരണത്തിൽ, സീറോ റിട്ടേൺ മൂല്യം പാറ്റേണിന്റെ സാന്നിധ്യത്തെ സൂചിപ്പിക്കുന്നു, അതേസമയം പൂജ്യമല്ലാത്ത മൂല്യം പാറ്റേണിന്റെ അഭാവത്തെ സൂചിപ്പിക്കുന്നു.
ചിലപ്പോൾ, പൊരുത്തപ്പെടുന്ന പാറ്റേണിന് ചുറ്റും കുറച്ച് വരികൾ കാണിക്കുന്നത് അർത്ഥമാക്കുന്നു. അത്തരം സാഹചര്യങ്ങൾക്കായി, നമുക്ക് കമാൻഡിന്റെ -B ഓപ്ഷൻ ഉപയോഗിക്കാം, അത് പൊരുത്തപ്പെടുന്ന പാറ്റേണിന് മുമ്പായി N ലൈനുകൾ പ്രദർശിപ്പിക്കുന്നു.
ഉദാഹരണത്തിന്, ചുവടെയുള്ള കമാൻഡ് പാറ്റേൺ പൊരുത്തം വിജയിക്കുന്ന വരിയും അതിന് മുമ്പുള്ള 2 വരികളും പ്രിന്റ് ചെയ്യും.
$ egrep -B 2 -n professionals sample.txt

ഈ ഉദാഹരണത്തിൽ, ലൈൻ നമ്പറുകൾ പ്രദർശിപ്പിക്കുന്നതിന് ഞങ്ങൾ -n ഓപ്ഷൻ ഉപയോഗിച്ചു.
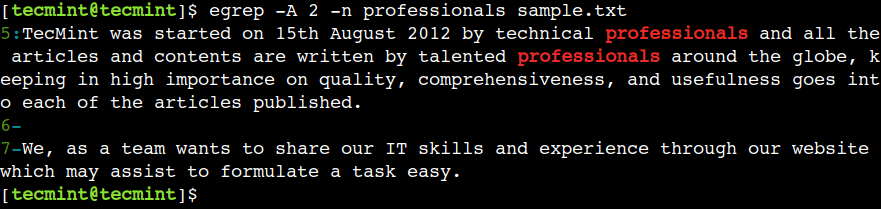
സമാനമായ രീതിയിൽ, പാറ്റേൺ പൊരുത്തപ്പെടുത്തലിന് ശേഷം ലൈനുകൾ പ്രദർശിപ്പിക്കുന്നതിന് കമാൻഡിന്റെ -A ഓപ്ഷൻ ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, ചുവടെയുള്ള കമാൻഡ് പാറ്റേൺ പൊരുത്തം വിജയിക്കുന്ന വരിയും അടുത്ത 2 വരികളും പ്രിന്റ് ചെയ്യും.
$ egrep -A 2 -n professionals sample.txt
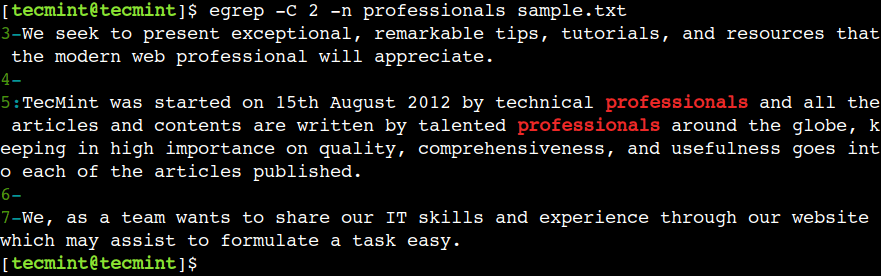
ഇതുകൂടാതെ, egrep കമാൻഡ് -C ഓപ്ഷനെ പിന്തുണയ്ക്കുന്നു, അത് -A, -B എന്നീ ഓപ്ഷനുകളുടെ പ്രവർത്തനക്ഷമത സംയോജിപ്പിക്കുന്നു, അത് പ്രദർശിപ്പിക്കുന്നു. പൊരുത്തപ്പെടുന്ന പാറ്റേണിന് മുമ്പും ശേഷവും വരികൾ.
$ egrep -C 2 -n professionals sample.txt
മുമ്പ് ചർച്ച ചെയ്തതുപോലെ, നമുക്ക് ഒന്നിലധികം ഫയലുകളിൽ പാറ്റേൺ പൊരുത്തപ്പെടുത്തൽ നടത്താം. എന്നിരുന്നാലും, ഒന്നിലധികം സബ് ഡയറക്ടറികൾക്ക് കീഴിൽ ഫയലുകൾ ഉണ്ടായിരിക്കുകയും അവയെല്ലാം ഞങ്ങൾ കമാൻഡ് ആർഗ്യുമെന്റുകളായി നൽകുകയും ചെയ്യുമ്പോൾ സ്ഥിതി സങ്കീർണ്ണമാകും.
അത്തരം സന്ദർഭങ്ങളിൽ, ഇനിപ്പറയുന്ന ഉദാഹരണത്തിൽ കാണിച്ചിരിക്കുന്നതുപോലെ -r ഓപ്ഷൻ ഉപയോഗിച്ച് നമുക്ക് ഒരു ആവർത്തന രീതിയിൽ പാറ്റേൺ പൊരുത്തപ്പെടുത്തൽ നടത്താം.
ആദ്യം, 2 ഉപ-ഡയറക്ടറികൾ സൃഷ്ടിച്ച് അവയിലേക്ക് sample.txt ഫയൽ പകർത്തുക:
$ mkdir -p dir1/dir2 $ cp sample.txt dir1/ $ cp sample.txt dir1/dir2/
ഇപ്പോൾ, നമുക്ക് തിരയൽ പ്രവർത്തനം ഒരു ആവർത്തന രീതിയിൽ നടത്താം:
$ egrep -r professionals dir1

മുകളിലെ ഉദാഹരണത്തിൽ, dir1/dir2/sample.txt, dir1/sample.txt ഫയലുകൾക്കായി പാറ്റേൺ പൊരുത്തം വിജയിച്ചതായി നമുക്ക് കാണാൻ കഴിയും.
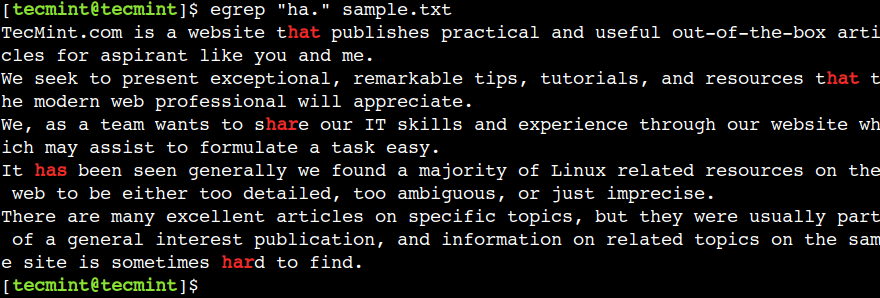
വരിയുടെ അവസാനം ഒഴികെയുള്ള ഏതെങ്കിലും ഒരു പ്രതീകവുമായി പൊരുത്തപ്പെടുന്നതിന് നമുക്ക് ഒരു ഡോട്ട് (.) പ്രതീകം ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, താഴെയുള്ള റെഗുലർ എക്സ്പ്രഷൻ ഹാർ, ഹാറ്റ് എന്നീ വാചകങ്ങളുമായി പൊരുത്തപ്പെടുന്നു, കൂടാതെ ഇവയുണ്ട്:
$ egrep "ha." sample.txt
മുമ്പത്തെ പ്രതീകത്തിന്റെ പൂജ്യമോ അതിലധികമോ സംഭവങ്ങളുമായി പൊരുത്തപ്പെടുത്താൻ നമുക്ക് നക്ഷത്രചിഹ്നം (*) ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, താഴെയുള്ള റെഗുലർ എക്സ്പ്രഷൻ, we എന്ന സ്ട്രിംഗ് അടങ്ങുന്ന ടെക്സ്റ്റുമായി പൊരുത്തപ്പെടുന്നു, തുടർന്ന് b എന്ന പ്രതീകത്തിന്റെ പൂജ്യമോ അതിലധികമോ സംഭവങ്ങൾ.
$ egrep "web*" sample.txt

മുമ്പത്തെ പ്രതീകത്തിന്റെ ഒന്നോ അതിലധികമോ സംഭവങ്ങൾ പൊരുത്തപ്പെടുത്താൻ ഞങ്ങൾക്ക് പ്ലസ് (+) ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, താഴെയുള്ള റെഗുലർ എക്സ്പ്രഷൻ, we എന്ന സ്ട്രിംഗ് അടങ്ങിയിരിക്കുന്ന ടെക്സ്റ്റുമായി പൊരുത്തപ്പെടുന്നു, തുടർന്ന് b എന്ന പ്രതീകത്തിന്റെ ഒരു സംഭവമെങ്കിലും.
$ egrep "web+" sample.txt
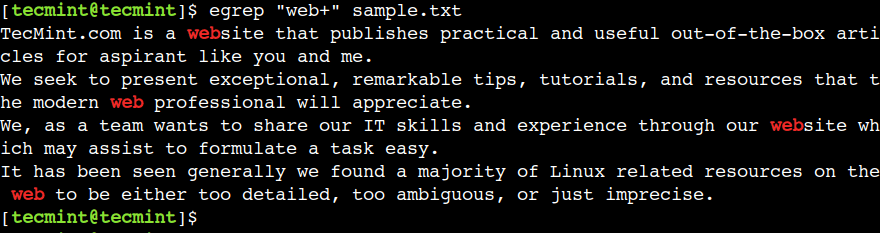
we, were, b എന്ന അക്ഷരത്തിന്റെ അഭാവം മൂലം - വാക്കുകൾക്ക് പാറ്റേൺ പൊരുത്തപ്പെടുത്തൽ വിജയിക്കുന്നില്ലെന്ന് ഇവിടെ കാണാം.
ലൈനിന്റെ ആരംഭത്തെ പ്രതിനിധീകരിക്കാൻ നമുക്ക് ക്യാരറ്റ് (^) ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, താഴെയുള്ള റെഗുലർ എക്സ്പ്രഷൻ, We എന്ന വാചകത്തിൽ ആരംഭിക്കുന്ന വരികൾ പ്രിന്റ് ചെയ്യുന്നു:
$ egrep "^We" sample.txt

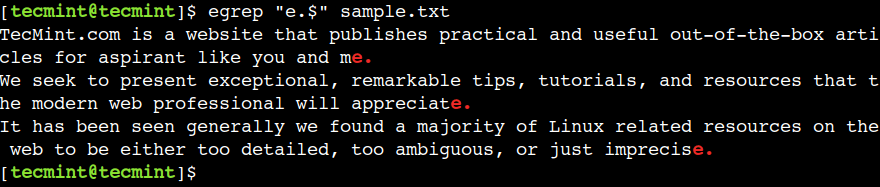
വരിയുടെ അവസാനത്തെ പ്രതിനിധീകരിക്കാൻ നമുക്ക് ഡോളർ ($) ഉപയോഗിക്കാം. ഉദാഹരണത്തിന്, താഴെയുള്ള റെഗുലർ എക്സ്പ്രഷൻ, e. എന്ന വാചകത്തിൽ അവസാനിക്കുന്ന വരികൾ പ്രിന്റ് ചെയ്യുന്നു:
$ egrep "e.$" sample.txt
ശൂന്യമായ വരിയെ പ്രതിനിധീകരിക്കാൻ നമുക്ക് ക്യാരറ്റ് (^) ഉടൻ തന്നെ ഡോളർ ($) ഉപയോഗിക്കാം. ശൂന്യമായ വരികൾ നീക്കം ചെയ്യാൻ നമുക്ക് ഇത് ഒരു സാധാരണ എക്സ്പ്രഷനിൽ ഉപയോഗിക്കാം:
$ egrep -n -v "^$" sample.txt
മുകളിലെ ഔട്ട്പുട്ടിൽ, 2, 4, 6, 8, 10 എന്നീ വരി നമ്പറുകൾ ശൂന്യമായതിനാൽ അവ പ്രദർശിപ്പിക്കപ്പെടുന്നില്ലെന്ന് നമുക്ക് കാണാൻ കഴിയും.
ഈ ലേഖനത്തിൽ, egrep കമാൻഡുകളുടെ ഉപയോഗപ്രദമായ ചില ഉദാഹരണങ്ങൾ ഞങ്ങൾ ചർച്ച ചെയ്തു. ഉൽപ്പാദനക്ഷമത മെച്ചപ്പെടുത്താൻ ഒരാൾക്ക് ദൈനംദിന ജീവിതത്തിൽ ഈ ഉദാഹരണങ്ങൾ ഉപയോഗിക്കാം.
ലിനക്സിലെ egrep കമാൻഡിന്റെ മറ്റേതെങ്കിലും മികച്ച ഉദാഹരണം നിങ്ങൾക്ക് അറിയാമോ? ചുവടെയുള്ള അഭിപ്രായങ്ങളിൽ നിങ്ങളുടെ വീക്ഷണങ്ങൾ ഞങ്ങളെ അറിയിക്കുക.